Binary search is amazingly fast to search and easy-to-implement. But this speed is limited to search. When the insertions into this sorted array are considerable, the speed falls down due to ‘O(n) insertion cost’. O(n) insertion can be removed by linked-lists but these can’t be used for random accesses.
So here we are stuck between easy insertions in the linked-lists vs the easy access from arrays. How do we strike a balance between both?
This is a write up on a popular data structure named Skip-lists which can help us do what we expect –
Introduction:
Skip-lists use linked-lists to search elements. Linked list traversal is O(n) complexity because it needs to visit every preceding element to reach a certain element. What if we find a way to reach a certain element without visiting every preceding element? That will surely reduce the complexity by a factor of ‘the number of elements’ we are skipping. But how do we implement this?
A basic model of Skip-list:
Look at the below diagram with two layers of linked list one above the other. There is one original linked list containing all the elements and then there is an express highway linked-list with some elements.
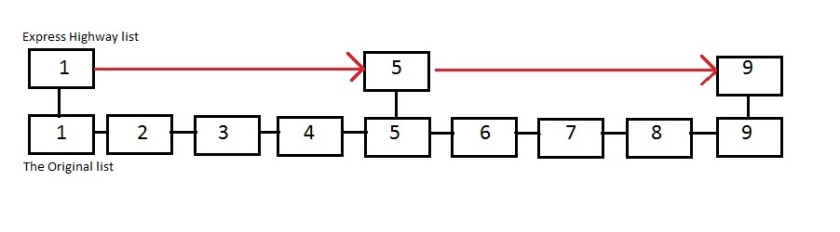
When we start searching for an element we start from the left end of the express list. There are three things that can happen:
1. The element is smaller than the required search element. We move to the next element in that express list.
2. The element is equal to the required search element. In this case, we return that the element is found.
3. The element is greater than the required search element. Here we move to the previous element of the express list. Move one step down to the below layer (original list) and continue the search in the lower list towards the right.
Complexity of Skip-lists:
In the worst case, it should go through all the elements in the express list + number of elements in the segment of the lower layer. A segment is – the “lower list” nodes between two “express list” nodes.
Why is this a parallel data structure?
At this point, you might be thinking about how this is better from a binary search tree. The reason is that the concurrent insertions and deletions on the binary search tree would spoil the integrity of the structure if no care is taken. This forces the algorithm to lock the structure whenever insertion or deletion is happening.
In skip-lists this does not happen because the structure is very simple and only local locks are needed to insert and delete.
Disadvantages:
Every structure has it’s own drawbacks. In skip-lists, there is a trade-off between space complexity and time complexity. The space complexity is due to the storage of extra express lists (pointers).
This is enough to get a good idea of what skip lists are. Continue if you want to get the idea of how skip lists can be parallelized.
Parallelizing skip-lists:
We will parallelize the insertion of the elements in the skip list. The serial code is in the following link.
Serial code
The parallelized version of code is here.
Parallel code
How the serial code is implemented?
The serial code is a probabilistic based algorithm(i.e creating levels in a probable manner). I have changed that to a balanced skip-list for a better comparison of serial and parallel code.
The serial code is implemented very smartly to reduce space storage. They use two structures in the code “skip-list” and “snode”. “skip-list” has the information of level, size and has a pointer to the header of the skip-list. Skip-list consists of snodes. “snode” stores the key-value pair and an extra forward array. This forward is very important as it contains information of the next node in a certain level. snode_name->forward[1] will give you the next node in the bottom list. snode_name->forward[2] if exists will give you the next node of the second list. Notice that this implementation is different than how I explained the skip-list in the figure above. In my explanation, I have duplicated nodes in the express list. Here it is not so. The above figure is implemented like this – node1->forward[1] is a pointer to node2 and node1->forward[2] is a pointer to node5.
How are insertions done?
The function starts from the head element of the top layer. It iterates through the top layer until it reaches the node having key greater than the key to be inserted. In this case, it drops to the layer below and starts going ahead in that layer.It keeps dropping this way to the bottom-most layer and stops one place behind the position it is going to insert. It stores all these ‘one step back nodes’ in an array called update. Then the actual insertions happen on different levels. The insertions are just like how you insert in the linked list.
How can insertions be parallelized?
We can insert elements using multiple threads but you should be careful here because there are race conditions. You can use multiple threads as long as changes done by one thread doesn’t affect the other.
How to be sure that there won’t be race conditions between threads?
“If a thread1 is inserting a node with key-value x then the thread2 can update anything which is smaller than the key value of the node before it without any race situations.”
For example, if you are inserting “7.5” in the above figure then you can parallelly insert “3.5” without any race conditions.
After parallelizing the stats are:
In the original code inserting elements when the list is huge took 25ms.
After parallelizing the same insertions, it took 17-18ms in 4 out of 5 times and 28ms in 1 out of 5 times. This variation is due to the fact that the thread execution is haphazard and the exact time can’t be predicted.
Serial code execution time:

Parallel code execution time:

Hardware details of the computer in which the code was executed:

Thanks for the article and for the software. In my case, the parallel version takes a bit longer (Intel core i7 6700k – 16GB RAM):
/tmp❯ ./skip_par
Insert:——————–
executing 0th thread,inserting 4000005 parallely
executing 1th thread,inserting 5000110 parallely
time taken 22.982084 ms
Search:——————–
key = 4000005, present
key = 5000110, present
/tmp❯ ./skip
Inserting:——————–
inserting 4000009 serially
inserting 5000008 serially
time taken 22.683502 ms
Search:——————–
key = 4000005, not found
key = 5000110, not found
LikeLike
Hi Dino, I know why this could be happening but just to verify my understanding can you try inserting 50000110 first and 4000005 second and tell me what stats you get?
And the stats which you are getting, are you getting the increase all the time?
LikeLike